In this article, we will discuss "Difference between Kinesis Data Stream and Kinesis Firehose". Today, I will explain the difference between Kinesis Data Stream and Kinesis Firehose. AWS constantly offering the new features and functionality. Kinesis is known as highly available communication channel to stream messages between data producers and data consumers.
Data Producers: Source of data such as system or web log data, social network data, financial data, mobile app data, telemetry from connected IoT devices, or etc.
Data Consumers: Data processing and storage applications such as Amazon Simple Storage Service (S3), Apache Hadoop, Apache Storm, ElasticSearch, or etc.
It is important to understand Kinesis first. Amazon Kinesis is a significant feature in AWS for easy collection, processing, and analysis of video and data streams in real-time environments. AWS Kinesis helps in real-time data ingestion with support for data such as video, audio, IoT telemetry data, application logs, analytics applications, website click-streams, and machine learning applications.
Kinesis Data Stream
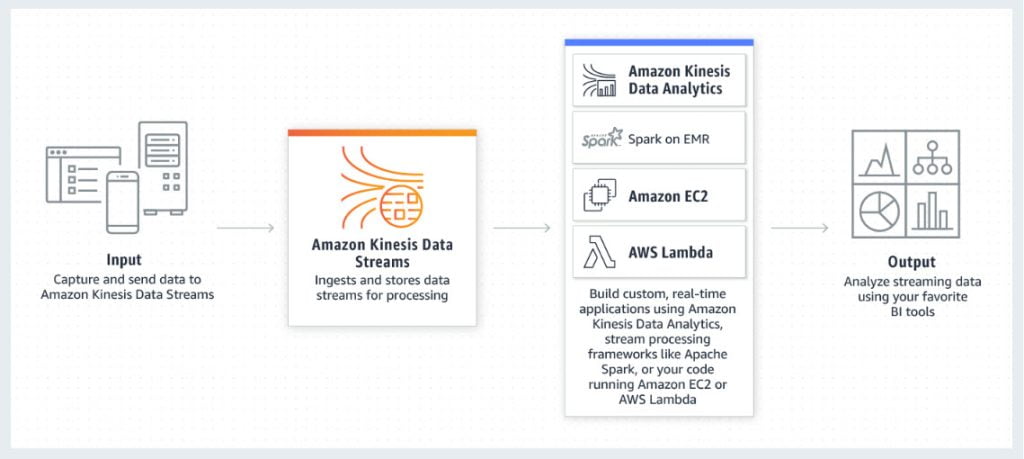
Amazon Kinesis Data Streams is used to collect and process large streams of data records in real time. There are no servers to manage. A typical Kinesis Data Streams application reads data from a data stream as data records. The on-demand mode eliminates the need to provision or manage capacity required for running applications. Adjust your capacity to stream gigabytes per second of data with Kinesis Data Streams. Get automatic provisioning and scaling with the on-demand mode. Pay only for what you use with Kinesis Data Streams. With the on-demand mode, you don't need to worry about over-provisioning. Use built-in integrations with other AWS services to create analytics, server-less, and application integration solutions on AWS quickly.
You can get more details on Amazon Kinesis Data Stream.
Amazon Kinesis Firehose
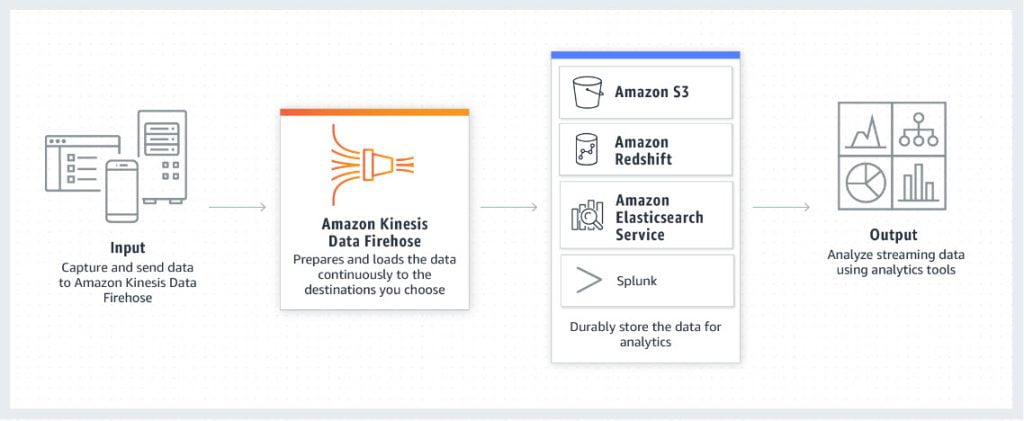
Amazon Kinesis Data Firehose is the easiest way to load streaming data into data stores and analytics tools. It is a fully managed service that makes it easy to capture, transform, and load massive volumes of streaming data from different sources into Amazon S3, Amazon Redshift, Amazon Open Search Service, Kinesis Data Analytics, generic HTTP endpoints, and etc.
You can get more details on Amazon Kinesis Firehose.
Differences Table - AWS Kinesis Data Streams and Data Firehose
| Kinesis Data Streams | Kinesis Data Firehose | |
| Objective | Kinesis Data Stream service for low-latency streaming and data ingestion at scale. | Data transfer service for loading streaming data into Amazon S3, Splunk, ElasticSearch, and RedShift. |
| Provisioning | Managed service yet requires configuration for shards. | Fully managed service without the need for any administration. |
| Processing | Real-time: processing capabilities with almost 200ms latency for classic tasks and almost 70ms latency for enhanced fan-out tasks. | Near real-time: processing capabilities, depending on the buffer size or minimum buffer time of 60 seconds. |
| Data Storage | We can configure storage for one to seven days. | No option given for data storage. |
| Scaling | Scaling through configuration of shards. | Automated scaling, according to the demand of users. |
| Replay Capabilities | Support relay capabilities. | No support for relay capability. |
| Data Producers | Need to write code for a producer with support for IoT, SDK, Kinesis Agent, CloudWatch, and KPL. | Need to write code for a producer with support for Kinesis Agent, IoT, KPL, CloudWatch, and Data Streams. |
| Data Consumers | Open-ended model for consumers with support for multiple consumers and destinations. Also, provides support for Spark and KCL. | Close-ended model for consumers and it's managed by Firehose. It does not provide any support for Spark or KCL. |
Conclusion
In this article, we are discussing "Difference between Kinesis Data Stream and Kinesis Firehose". I hope, you like this article and learn a lot. You can choose in between AWS Kinesis Data Streams or Firehose as per your uses and requirements. Please feel free to add comments if any queries or suggestions.
Keep learning & stay safe :)
You may like:
How to Setup Amazon Kinesis Data Stream with Amazon Pinpoint
How to use SSH with EC2 Instance
Comments
Post a Comment